LLM, RAG, agents : démystifier les concepts IA qui envahissent le dev
LLM, RAG, agents, embeddings, MCP - ces termes circulent partout dans les discussions tech. Mais derrière le jargon, que signifient-ils vraiment ? Et surtout, quand les utiliser, et quand s'en méfier ?
Il y a un problème avec la manière dont le monde tech parle d’IA en ce moment. Chaque semaine apporte son lot de nouveaux acronymes, chaque article suppose que le lecteur sait déjà de quoi il s’agit, et les discussions mélangent allègrement des concepts qui n’ont pas grand-chose à voir les uns avec les autres.
Le résultat : beaucoup de développeurs se retrouvent à utiliser des outils IA sans vraiment comprendre ce qu’ils font sous le capot. Ce qui fonctionne pour les tâches simples. Mais qui devient un problème dès qu’il faut déboguer, optimiser ou choisir la bonne approche pour un projet.
Voici une explication directe des concepts qui reviennent le plus souvent, dans l’ordre où ils ont du sens à comprendre.
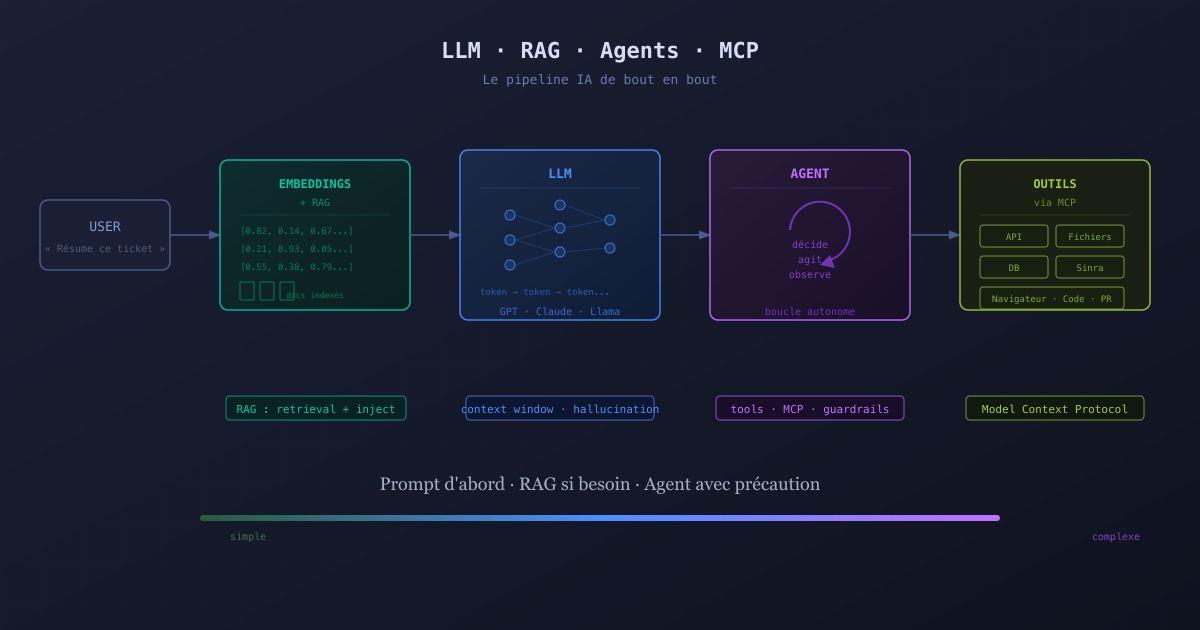
LLM : le socle de tout
Un LLM (Large Language Model) est un modèle statistique entraîné sur d’enormes quantités de texte. Son fonctionnement fondamental : prédire le prochain token (unité de texte) à partir du contexte précédent. C’est tout.
De cette mécanique simple émergent des capacités surprenantes : résumé, traduction, génération de code, raisonnement, réponse à des questions. GPT-4, Claude, Llama, Mistral - ce sont tous des LLMs.
L’exemple concret : tu envoies « Résume ce texte en trois points » suivi d’un article, le LLM produit un résumé. Il ne « comprend » pas le texte au sens humain. Il génère une réponse statistiquement cohérente avec ce que des humains auraient écrit dans ce contexte.
La limite à connaître : les LLMs hallucinent. Ils inventent des faits avec la même assurance qu’ils en énoncent de vrais. Leur connaissance est figée à leur date d’entraînement. Et ils n’ont aucune mémoire entre deux conversations, sauf si tu la leur fournis explicitement.
Prompt engineering : l’art de bien demander
Le prompt est l’instruction que tu envoies au LLM. Le prompt engineering est la discipline qui consiste à formuler ces instructions de façon à obtenir un résultat fiable et de qualité.
Quelques techniques qui font une vraie différence :
- Few-shot : donner des exemples dans le prompt. « Voici trois exemples de ce que je veux, maintenant fais pareil pour ce cas-ci. »
- Chain-of-thought : demander au modèle de raisonner étape par étape avant de répondre. Améliore significativement les performances sur les tâches complexes.
- System prompt : instruction de contexte en amont, qui définit le rôle et le comportement du modèle pour toute la conversation.
La limite à connaître : le prompt engineering est fragile. Un modèle change, et tes prompts peuvent se comporter différemment. C’est difficile à tester de façon systématique, et les petites variations de formulation peuvent avoir des effets importants.
Embeddings : représenter le sens sous forme de nombres
Un embedding est une représentation vectorielle d’un texte. Concrètement : transformer une phrase en une liste de nombres (souvent plusieurs centaines ou milliers de dimensions) qui capture son sens sémantique.
Ce qui rend les embeddings utiles : deux textes sémantiquement proches auront des vecteurs proches dans cet espace mathématique. « chien » et « canin » auront des vecteurs plus proches que « chien » et « voiture ».
L’exemple concret : tu indexes toute ta documentation technique en embeddings. Quand un utilisateur pose une question, tu calcules l’embedding de sa question et tu cherches les documents dont les embeddings sont les plus proches. Tu retrouves ainsi les passages pertinents, même si la formulation exacte diffère.
La limite à connaître : les embeddings mesurent la similarité sémantique, pas la pertinence logique. Deux phrases peuvent être proches sémantiquement tout en étant en contradiction. La qualité de tes embeddings dépend aussi du modèle utilisé pour les générer.
RAG : donner de la mémoire et des données fraîches au LLM
RAG signifie Retrieval-Augmented Generation. Le principe : avant d’appeler le LLM, on recherche les documents pertinents (via embeddings ou recherche classique) et on les injecte dans le contexte de la requête.
C’est la réponse au problème le plus courant avec les LLMs : ils ne savent pas ce qui s’est passé après leur date d’entraînement, et ils ne connaissent pas vos données internes.
L’exemple concret : un chatbot qui répond aux questions sur la documentation interne de ton équipe. Sans RAG, il invente des réponses. Avec RAG, on récupère d’abord les pages de doc pertinentes, puis on demande au LLM de répondre en s’appuyant sur ces pages. Le résultat est ancré dans des données réelles.
Pipeline typique :
- L’utilisateur pose une question
- On calcule l’embedding de la question
- On cherche les documents les plus proches dans la base vectorielle
- On injecte ces documents dans le prompt
- Le LLM génère une réponse en s’appuyant sur ces documents
La limite à connaître : la qualité du RAG est directement liée à la qualité du retrieval. Si tu récupères les mauvais documents, le LLM produira une mauvaise réponse avec beaucoup de confiance. « Garbage in, garbage out » s’applique ici à pleine puissance.
Context window : la mémoire de travail du LLM
La context window est la quantité maximale de texte qu’un LLM peut « voir » en même temps : l’historique de la conversation, les documents injectés via RAG, le system prompt, tout ça ensemble doit tenir dans cette fenêtre.
Elle se mesure en tokens. Les modèles récents ont des context windows de 128k à 1 million de tokens, ce qui correspond à des centaines de pages de texte.
Pourquoi c’est important : la context window dicte ta stratégie RAG. Si ta fenêtre est grande, tu peux injecter plus de documents et être moins sélectif. Si elle est petite, tu dois être précis dans ce que tu récupères. Et chaque token dans la fenêtre a un coût - financier et en latence.
Agents : le LLM qui agit
Un agent est un LLM équipé d’outils et capable de prendre des décisions en boucle. Au lieu de répondre à une question et de s’arrêter là, l’agent peut appeler des fonctions, consulter des APIs, lire des fichiers, et enchaîner plusieurs actions pour accomplir une tâche.
L’exemple concret : un agent qui reçoit un ticket Sinra décrivant un bug. Il lit le ticket, cherche les fichiers de code concernés, identifie le problème, écrit un correctif, lance les tests, et ouvre une pull request. Tout ça de façon autonome, en décidant à chaque étape de l’action suivante.
La boucle typique d’un agent :
- Lire l’objectif
- Décider quelle action prendre (appeler un outil, chercher de l’info, générer du texte)
- Exécuter l’action
- Observer le résultat
- Recommencer jusqu’à l’objectif atteint (ou jusqu’à un échec)
La limite à connaître : les agents sont puissants et peu fiables sur des tâches longues. Ils peuvent se bloquer en boucles, prendre de mauvaises décisions en cascade, et les erreurs s’accumulent. Plus la tâche est longue, plus le risque de dérapage est élevé. Les coûts peuvent aussi s’envoler rapidement. À utiliser avec des garde-fous clairs.
MCP : le standard pour connecter les outils aux agents
MCP (Model Context Protocol) est un protocole ouvert développé par Anthropic pour standardiser la façon dont les LLMs interagissent avec des outils et des services externes.
Sans standard, chaque intégration (LLM + outil) est une implémentation custom. MCP définit une interface commune : le LLM sait comment demander à utiliser un outil, l’outil sait comment exposer ses capacités, et l’intégration est réutilisable.
L’exemple concret : un serveur MCP expose les capabilities de Sinra. L’agent peut alors lire les issues, créer des cycles, mettre à jour des statuts - sans que chaque développeur ait à écrire l’intégration depuis zéro.
C’est l’équivalent d’une API standardisée pour le monde des agents. En 2026, MCP est adopté par la majorité des outils dev majeurs.
Fine-tuning : spécialiser un modèle
Le fine-tuning consiste à reprendre un LLM existant et à le ré-entraîner sur tes propres données pour adapter son comportement à ton cas d’usage. Le modèle apprend un style de réponse, un domaine de spécialité, ou un format particulier.
Quand ça a du sens : quand tu veux modifier le ton ou le style de façon systématique. Quand les performances sur un domaine très spécifique sont insuffisantes avec du prompt engineering seul. Quand tu as des milliers d’exemples de qualité pour entraîner.
La limite à connaître : le fine-tuning ne sert pas à « apprendre des faits » au modèle. Pour lui donner accès à des informations précises et à jour, le RAG est presque toujours meilleur choix. Le fine-tuning est coûteux, long, et les gains sont souvent inférieurs à ce qu’on espérait.
Par où commencer : la règle d’escalade
Face à un problème à résoudre avec l’IA, la règle est simple :
D’abord : un bon prompt. Souvent suffisant pour 80% des cas d’usage. Simple à itérer, pas de coût d’infrastructure.
Si les données manquent ou sont obsolètes : ajouter du RAG. Indexe ta documentation, tes tickets, ta base de connaissance. Le LLM répondra en s’appuyant sur des faits réels.
Si des actions sont nécessaires : construire un agent. Avec des outils bien définis, des garde-fous clairs, et en commençant par des tâches courtes et vérifiables.
Si le comportement doit changer en profondeur : envisager le fine-tuning. En dernier recours, avec des données de qualité.
Le piège courant : sauter directement aux agents parce que c’est excitant, sans avoir d’abord essayé un prompt simple. La complexité a un coût réel - en maintenance, en débogage, en coûts d’API.
Ce que ça change pour une équipe produit
Pour une équipe qui utilise Sinra au quotidien, ces outils peuvent avoir un impact concret sur des tâches répétitives : générer un premier jet de spec à partir d’une description, résumer l’activité d’un cycle, suggérer des labels pour un nouveau ticket, identifier des capabilities similaires déjà existantes.
La clé : rester lucide sur ce que le LLM fait réellement. Il produit du texte probable. Il ne comprend pas ton contexte business. Il ne se souvient pas de la décision prise il y a trois semaines sauf si tu la lui fournis.
Utilisé avec cette lucidité, l’IA devient un accélérateur réel. Utilisé sans elle, c’est une source de confiance non méritée dans des outputs qui demandent à être vérifiés.
Prêt à Transformer Votre Gestion de Projet ?
Appliquez ces insights avec Sinra - la plateforme unifiée pour les équipes modernes.
Commencer l'Essai Gratuit