Trunk-based development vs feature branches : lequel choisir ?
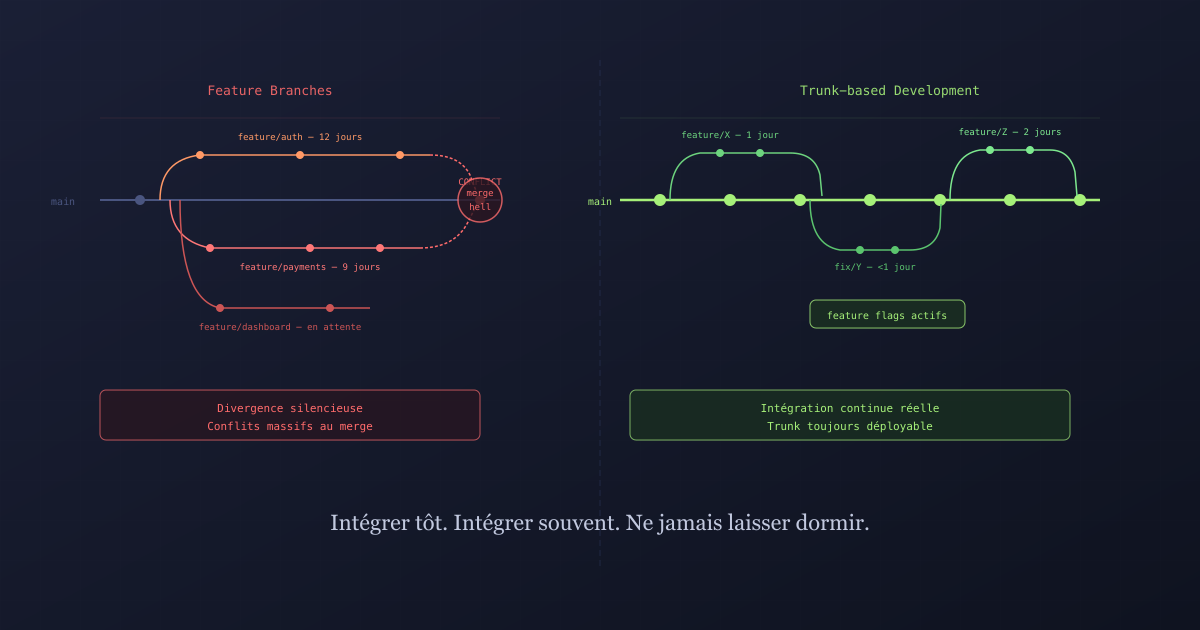
Les feature branches longues semblent sûres. Elles permettent de travailler à l'abri, sans perturber les autres. Jusqu'au jour du merge, où tout s'effondre. Le trunk-based development propose une autre approche : intégrer tôt, intégrer souvent, et ne jamais laisser du code dormir trop longtemps.
Lundi, tu crées une branche pour ta nouvelle feature. Vendredi, tu essaies de merger. Le conflit fait 400 lignes. Tu passes l’après-midi à démêler ce que tes collègues ont fait pendant que tu travaillais dans ton coin. Le CI est rouge. La revue de code prend deux heures parce que personne ne se souvient de ce que tu avais expliqué au début de la semaine.
Ce scénario a un nom : merge hell. Et il a une cause identifiable : les feature branches longues.
Le problème des branches longues
Une feature branch longue, c’est une branche qui vit plusieurs jours ou plusieurs semaines en parallèle du reste du code. Sur le papier, l’intention est bonne : isoler le travail en cours pour ne pas déstabiliser la base de code principale. En pratique, ce qui semble sûr crée exactement le problème qu’on voulait éviter.
Pendant que tu travailles sur ta branche, le reste de l’équipe avance sur la leur. Les deux bases de code divergent silencieusement. Personne ne voit les conflits qui s’accumulent. Quand vient le moment de merger, tu ne fais pas qu’intégrer ton code : tu intègres plusieurs jours de divergence simultanée.
Plus la branche est longue, plus le merge est douloureux. C’est une règle quasi-mécanique.
Il y a un autre effet moins visible : le code en cours de développement sur des branches longues n’est pas testé dans le contexte réel de la base de code. Les tests d’intégration tournent sur des snapshots qui s’éloignent de plus en plus de la réalité. Tu découvres des problèmes tard, quand ils coûtent cher à corriger.
Ce qu’est le trunk-based development
Le trunk-based development est une pratique où tous les développeurs intègrent leur code sur la branche principale (le « trunk », souvent main ou master) plusieurs fois par jour. Les branches existent, mais elles sont courtes : au maximum un ou deux jours de vie.
L’idée centrale : si l’intégration est douloureuse, la solution n’est pas de l’éviter mais de la faire plus souvent. Plus tu intègres fréquemment, plus les conflits sont petits et simples à résoudre.
Concrètement, ça ressemble à ça :
- Tu travailles sur une petite unité de code (une fonction, un endpoint, une migration de base de données).
- Tu crées une branche, tu codes, tu ouvres une pull request dans la journée.
- La revue est rapide parce que le diff est petit et le contexte est frais.
- Tu merges dans la journée ou le lendemain.
- Tu passes à la prochaine unité.
Le trunk est toujours dans un état déployable. L’intégration continue n’est pas un concept flottant : c’est une réalité mécanique.
Le rôle des feature flags
Le principal contre-argument au trunk-based development : « Et si la feature n’est pas terminée quand on merge ? »
C’est une vraie question. La réponse, c’est les feature flags.
Un feature flag est un interrupteur qui active ou désactive du code en production. Tu peux merger du code incomplet sur le trunk, l’entourer d’un flag désactivé, et l’exposer progressivement quand il est prêt. Les utilisateurs ne voient rien tant que le flag est fermé. Ton équipe peut tester en production sur un sous-ensemble. Tu peux rollback en une seconde sans redéployer.
Les feature flags découplent le déploiement de la livraison. Déployer (mettre le code en prod) devient distinct de livrer (activer la feature pour les utilisateurs). C’est une distinction qui change profondément la gestion du risque.
Avantages concrets du trunk-based development
Les conflits sont petits. Quand tu intègres plusieurs fois par jour, chaque intégration touche peu de code. Les conflits, quand il y en a, se résolvent en minutes.
Les revues de code sont utiles. Un diff de 30 lignes sur une branche ouverte hier est reviewable. Un diff de 800 lignes sur une branche ouverte il y a deux semaines est une formalité dont tout le monde veut se débarrasser.
L’intégration continue est réelle. Le CI ne valide pas du code isolé : il valide l’état actuel de l’ensemble du système. Les régressions apparaissent immédiatement, pas le vendredi soir avant une release.
Il y a moins de code en cours. Le work in progress diminue. L’équipe travaille sur des choses qui avancent réellement plutôt que sur des branches qui attendent de merger.
La base de code est toujours déployable. Tu peux déployer à n’importe quel moment. Pas besoin de planifier une « fenêtre de merge » ou de geler les développements avant une release.
Quand les feature branches longues ont du sens
Le trunk-based development n’est pas universel. Il y a des contextes où les branches longues sont justifiées, voire nécessaires.
Les projets open source. Quand des contributeurs externes soumettent du code, tu ne peux pas leur demander d’intégrer directement sur le trunk. Les pull requests longues existent pour permettre la revue de contributions dont tu ne contrôles pas la cadence.
Les équipes avec un processus de revue lent. Si la revue de code prend systématiquement plusieurs jours parce que les reviewers sont débordés, garder des branches courtes est difficile. Mais dans ce cas, le problème à résoudre n’est pas le branching : c’est la capacité de revue.
Les changements structurels majeurs. Une migration d’architecture, un remplacement de librairie fondamentale : ces travaux nécessitent parfois une branche dédiée. Mais même là, des techniques comme les « branch by abstraction » permettent d’intégrer progressivement sur le trunk sans branche longue.
La résistance habituelle
« On ne peut pas faire du trunk-based, on a trop de features en parallèle. »
C’est souvent l’inverse : les features en parallèle sur des branches longues créent exactement la complexité qui rend tout difficile. Moins de work in progress simultané, avec des cycles plus courts, simplifie mécaniquement l’intégration.
« Les développeurs ne sont pas à l’aise avec ça. »
C’est une question d’habitude. La plupart des développeurs qui ont travaillé en trunk-based ne veulent plus revenir aux branches longues. La friction du changement est réelle, mais elle est temporaire.
« On a besoin des branches pour la revue de code. »
La revue de code ne nécessite pas des branches longues. Elle nécessite des pull requests - qui peuvent être ouvertes et mergées dans la journée.
Le lien avec des cycles courts
Le trunk-based development fonctionne naturellement avec des cycles de livraison courts. Quand ton équipe travaille avec des cycles bien définis, avec des objectifs clairs pour chaque itération, le découpage du travail en petites unités intégrables devient la façon naturelle de travailler.
Dans Sinra, les cycles permettent de définir précisément ce qui est en cours à un instant donné. Les issues sont les unités de travail. Les capabilities regroupent les features à livrer dans une release. Cette structure favorise naturellement les branches courtes : chaque issue correspond à une unité de travail qui peut être intégrée rapidement, sans attendre que plusieurs semaines de développement s’accumulent.
Les releases sont ainsi composées de code qui a déjà été intégré et validé, pas de branches qui se battent pour avoir raison au dernier moment.
En pratique : comment commencer
Si ton équipe travaille actuellement avec des branches longues, le passage au trunk-based development se fait progressivement.
Commence par réduire la durée de vie maximale des branches. Fixe une règle : aucune branche ne peut vivre plus de deux jours sans être mergée ou découpée. Ça force à découper le travail différemment.
Ensuite, installe un système de feature flags si tu n’en as pas. C’est le filet de sécurité qui permet d’intégrer du code non terminé sans risque pour les utilisateurs.
Améliore la vitesse de revue. Si les PRs attendent deux jours avant d’être reviewées, le trunk-based ne fonctionnera pas. La revue doit être une priorité, pas une interruption.
Enfin, mesure. Le lead time for changes (temps entre le premier commit et le déploiement en prod) est une métrique directe de l’efficacité de ton processus d’intégration. Si ce temps diminue, tu vas dans la bonne direction.
Le trunk-based development n’est pas une règle absolue. C’est une direction : intégrer plus souvent, garder les branches courtes, ne jamais laisser du code dormir. La douleur des merges n’est pas inévitable. Elle est le symptôme d’une intégration trop rare.
Prêt à Transformer Votre Gestion de Projet ?
Appliquez ces insights avec Sinra - la plateforme unifiée pour les équipes modernes.
Commencer l'Essai Gratuit