LLM, RAG, agentes: desmitificar los conceptos IA que invaden el desarrollo
LLM, RAG, agentes, embeddings, MCP - estos términos están en todas partes en las discusiones tech. Pero detrás del jargon, ¿qué significan realmente? Y sobre todo, ¿cuándo usarlos y cuándo desconfiar?
Hay un problema con la forma en que el mundo tech habla de IA ahora mismo. Cada semana trae su lote de nuevos acrónimos, cada artículo asume que el lector ya sabe de qué se trata, y las discusiones mezclan conceptos que no tienen mucho que ver entre sí.
El resultado: muchos desarrolladores terminan usando herramientas IA sin entender realmente lo que hacen bajo el capó. Esto funciona para tareas simples. Pero se convierte en un problema cuando hay que depurar, optimizar o elegir el enfoque correcto para un proyecto.
Aquí hay una explicación directa de los conceptos que aparecen con más frecuencia, en el orden que tiene sentido comprenderlos.
LLM: la base de todo
Un LLM (Large Language Model) es un modelo estadístico entrenado en enormes cantidades de texto. Su mecanismo fundamental: predecir el siguiente token (unidad de texto) a partir del contexto previo. Eso es todo.
De este mecanismo simple emergen capacidades sorprendentes: resumen, traducción, generación de código, razonamiento, respuesta a preguntas. GPT-4, Claude, Llama, Mistral - todos son LLMs.
El ejemplo concreto: envías «Resume este texto en tres puntos» seguido de un artículo, el LLM produce un resumen. No «entiende» el texto en el sentido humano. Genera una respuesta estadísticamente coherente con lo que los humanos habrían escrito en ese contexto.
El límite a conocer: los LLMs alucinan. Inventan hechos con la misma seguridad que enuncian los reales. Su conocimiento está congelado en su fecha de entrenamiento. Y no tienen memoria entre conversaciones, salvo que se la proporciones explícitamente.
Prompt engineering: el arte de preguntar bien
El prompt es la instrucción que envías al LLM. El prompt engineering es la disciplina de formular estas instrucciones de forma que produzca resultados fiables y de calidad.
Algunas técnicas que hacen una diferencia real:
- Few-shot: dar ejemplos en el prompt. «Aquí hay tres ejemplos de lo que quiero, ahora haz lo mismo para este caso.»
- Chain-of-thought: pedir al modelo que razone paso a paso antes de responder. Mejora significativamente el rendimiento en tareas complejas.
- System prompt: instrucción de contexto inicial que define el rol y el comportamiento del modelo para toda la conversación.
El límite a conocer: el prompt engineering es frágil. Un modelo cambia y tus prompts pueden comportarse diferente. Es difícil de testear de forma sistemática, y pequeñas variaciones en la formulación pueden tener grandes efectos.
Embeddings: representar el significado como números
Un embedding es una representación vectorial de un texto. Concretamente: transformar una frase en una lista de números (a menudo varios cientos o miles de dimensiones) que captura su significado semántico.
Lo que hace útiles a los embeddings: dos textos semánticamente cercanos tendrán vectores cercanos en este espacio matemático. «perro» y «canino» tendrán vectores más cercanos que «perro» y «coche».
El ejemplo concreto: indexas toda tu documentación técnica como embeddings. Cuando un usuario hace una pregunta, calculas el embedding de su pregunta y buscas los documentos cuyos embeddings son más cercanos. Recuperas los pasajes relevantes, aunque la formulación exacta difiera.
El límite a conocer: los embeddings miden la similaridad semántica, no la relevancia lógica. Dos frases pueden ser semánticamente cercanas mientras son contradictorias. La calidad de tus embeddings también depende del modelo usado para generarlos.
RAG: dar memoria y datos frescos al LLM
RAG significa Retrieval-Augmented Generation. El principio: antes de llamar al LLM, se buscan los documentos relevantes (via embeddings o búsqueda clásica) y se inyectan en el contexto de la solicitud.
Es la respuesta al problema más común con los LLMs: no saben lo que pasó después de su fecha de entrenamiento, y no conocen tus datos internos.
El ejemplo concreto: un chatbot que responde preguntas sobre la documentación interna de tu equipo. Sin RAG, inventa respuestas. Con RAG, se recuperan primero las páginas de doc relevantes, luego se pide al LLM que responda basándose en esas páginas. El resultado está anclado en datos reales.
Pipeline típico:
- El usuario hace una pregunta
- Se calcula el embedding de la pregunta
- Se buscan los documentos más cercanos en la base vectorial
- Se inyectan esos documentos en el prompt
- El LLM genera una respuesta apoyándose en esos documentos
El límite a conocer: la calidad del RAG está directamente ligada a la calidad del retrieval. Si recuperas los documentos equivocados, el LLM producirá una mala respuesta con mucha confianza. «Basura entra, basura sale» aplica aquí a plena potencia.
Context window: la memoria de trabajo del LLM
La context window es la cantidad máxima de texto que un LLM puede «ver» al mismo tiempo: el historial de la conversación, los documentos inyectados via RAG, el system prompt - todo eso junto debe caber en esta ventana.
Se mide en tokens. Los modelos recientes tienen context windows de 128k a 1 millón de tokens, lo que corresponde a cientos de páginas de texto.
Por qué importa: la context window dicta tu estrategia RAG. Si tu ventana es grande, puedes inyectar más documentos y ser menos selectivo. Si es pequeña, debes ser preciso en lo que recuperas. Y cada token en la ventana tiene un coste, tanto financiero como en latencia.
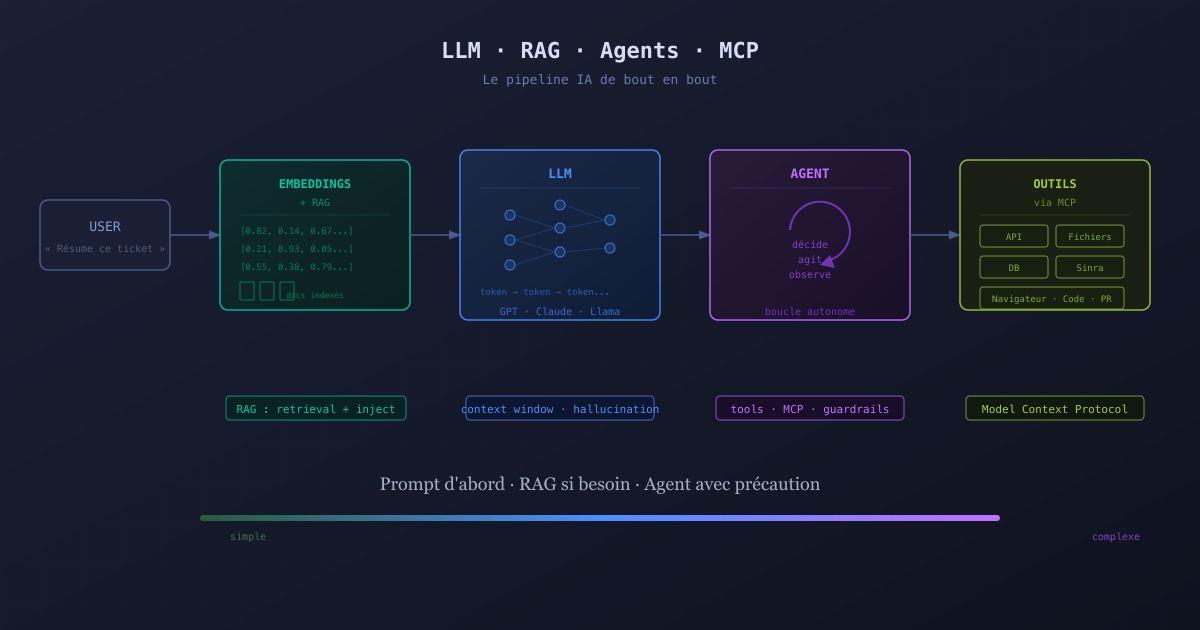
Agentes: el LLM que actúa
Un agente es un LLM equipado con herramientas y capaz de tomar decisiones en bucle. En lugar de responder una pregunta y detenerse ahí, el agente puede llamar funciones, consultar APIs, leer archivos, y encadenar múltiples acciones para cumplir una tarea.
El ejemplo concreto: un agente que recibe un ticket de Sinra describiendo un bug. Lee el ticket, busca los archivos de código relevantes, identifica el problema, escribe un fix, lanza los tests, y abre una pull request. Todo de forma autónoma, decidiendo en cada paso qué acción tomar a continuación.
El bucle típico de un agente:
- Leer el objetivo
- Decidir qué acción tomar (llamar una herramienta, buscar info, generar texto)
- Ejecutar la acción
- Observar el resultado
- Repetir hasta alcanzar el objetivo (o hasta un fallo)
El límite a conocer: los agentes son potentes y poco fiables en tareas largas. Pueden bloquearse en bucles, tomar malas decisiones en cascada, y los errores se acumulan. Cuanto más larga es la tarea, mayor es el riesgo de descarrilarse. Los costes también pueden dispararse rápidamente. Usar con salvaguardas claras.
MCP: el estándar para conectar herramientas a agentes
MCP (Model Context Protocol) es un protocolo abierto desarrollado por Anthropic para estandarizar cómo los LLMs interactúan con herramientas y servicios externos.
Sin un estándar, cada integración (LLM + herramienta) es una implementación personalizada. MCP define una interfaz común: el LLM sabe cómo pedir usar una herramienta, la herramienta sabe cómo exponer sus capacidades, y la integración es reutilizable.
El ejemplo concreto: un servidor MCP expone las capabilities de Sinra. El agente puede entonces leer issues, crear cycles, actualizar statuses - sin que cada desarrollador tenga que escribir la integración desde cero.
Es el equivalente de una API estandarizada para el mundo de los agentes. En 2026, MCP está adoptado por la mayoría de las principales herramientas dev.
Fine-tuning: especializar un modelo
El fine-tuning consiste en tomar un LLM existente y re-entrenarlo con tus propios datos para adaptar su comportamiento a tu caso de uso. El modelo aprende un estilo de respuesta, un dominio de especialidad, o un formato particular.
Cuándo tiene sentido: cuando quieres modificar el tono o estilo de forma sistemática. Cuando el rendimiento en un dominio muy específico es insuficiente con prompt engineering solo. Cuando tienes miles de ejemplos de calidad para entrenar.
El límite a conocer: el fine-tuning no sirve para «enseñar hechos» al modelo. Para darle acceso a información precisa y actualizada, el RAG es casi siempre mejor opción. El fine-tuning es costoso, lento, y los beneficios suelen ser menores de lo esperado.
Por dónde empezar: la regla de escalada
Ante un problema a resolver con IA, la regla es simple:
Primero: un buen prompt. A menudo suficiente para el 80% de los casos de uso. Simple de iterar, sin coste de infraestructura.
Si faltan datos o están desactualizados: añadir RAG. Indexa tu documentación, tus tickets, tu base de conocimiento. El LLM responderá apoyándose en hechos reales.
Si se necesitan acciones: construir un agente. Con herramientas bien definidas, salvaguardas claras, y empezando con tareas cortas y verificables.
Si el comportamiento debe cambiar en profundidad: considerar el fine-tuning. Como último recurso, con datos de calidad.
La trampa común: saltar directamente a los agentes porque es emocionante, sin haber probado primero un prompt simple. La complejidad tiene un coste real - en mantenimiento, en depuración, en costes de API.
Lo que esto cambia para un equipo de producto
Para un equipo que usa Sinra en el día a día, estas herramientas pueden tener un impacto concreto en tareas repetitivas: generar un primer borrador de spec a partir de una descripción, resumir la actividad de un cycle, sugerir labels para un nuevo ticket, identificar capabilities similares ya existentes.
La clave: mantener la claridad sobre lo que el LLM hace realmente. Produce texto probable. No entiende tu contexto de negocio. No recuerda la decisión tomada hace tres semanas salvo que se la proporciones.
Usado con esta claridad, la IA se convierte en un acelerador real. Usado sin ella, es una fuente de confianza no merecida en outputs que necesitan ser verificados.
¿Listo para Transformar su Gestión de Proyectos?
Aplique estos insights con Sinra, la plataforma unificada para equipos modernos.
Iniciar Prueba Gratuita