DORA metrics: las 4 métricas que realmente miden el rendimiento de un equipo
Velocidad, story points, tickets cerrados: estos números no dicen nada sobre la salud de un equipo. Las DORA metrics, en cambio, están correlacionadas con resultados de negocio reales. Aquí te explicamos por qué cambian la conversación.
Tu equipo entrega 40 story points por sprint. El backlog avanza. Los tickets se cierran. Y aun así, los usuarios llevan seis meses esperando funcionalidades, los incidentes en producción se multiplican, y cada despliegue genera ansiedad colectiva. Algo no funciona bien.
El problema no es el equipo. El problema es lo que mides.
Velocidad, story points, tickets cerrados: estas métricas miden actividad. No entrega de valor. No fiabilidad del sistema. No la capacidad real del equipo para hacer avanzar un producto.
Las DORA metrics existen precisamente para solucionar este problema.
¿De dónde vienen las DORA metrics?
DORA significa DevOps Research and Assessment. Es un programa de investigación lanzado por Google que analizó, durante varios años, las prácticas de miles de equipos de desarrollo en empresas de todos los tamaños.
El objetivo era simple: encontrar qué prácticas y métricas se correlacionan realmente con el rendimiento organizacional. No lo que la gente cree que funciona. Lo que realmente funciona, medido en datos reales.
El resultado: 4 métricas que resultaron ser predictores fiables del rendimiento empresarial - rentabilidad, cuota de mercado, satisfacción del cliente y capacidad para alcanzar los objetivos organizacionales.
Estas 4 métricas no miden si el equipo está ocupado. Miden si el equipo entrega.
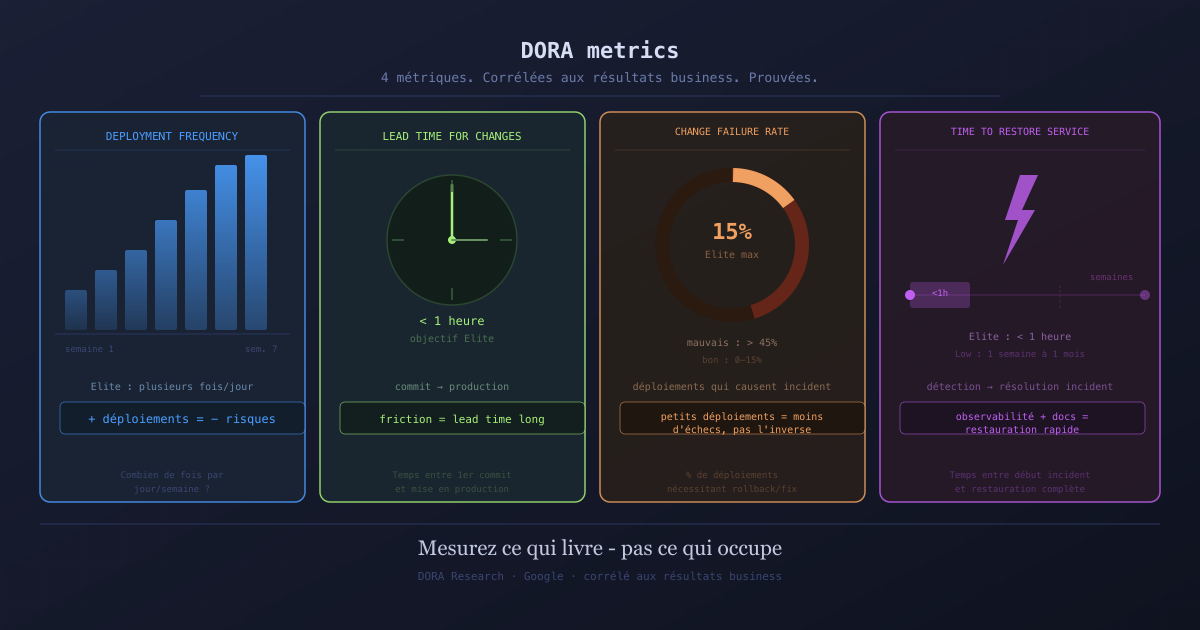
Las 4 métricas DORA
1. Deployment Frequency: ¿con qué frecuencia desplegáis?
La frecuencia de despliegue mide cuántas veces un equipo pone código en producción en un período determinado.
Los equipos Elite despliegan varias veces al día. Los equipos de bajo rendimiento despliegan una vez al mes o menos.
No es una cuestión del tamaño de la empresa o del sector. Es una cuestión de prácticas: trunk-based development, feature flags, pipelines CI/CD maduros. Cuando estas prácticas están en marcha, desplegar se convierte en un acto rutinario. Cuando faltan, cada despliegue es un evento arriesgado que se pospone.
La ironía: cuanto más se retrasan los despliegues, más arriesgados se vuelven, lo que empuja a retrasarlos aún más.
2. Lead Time for Changes: ¿cuánto tiempo del commit a producción?
El lead time for changes mide el retraso entre el momento en que un desarrollador escribe código y el momento en que ese código está en producción y disponible para los usuarios.
Este retraso incluye: revisión de código, pruebas automatizadas, procesos de aprobación y el propio despliegue.
Los equipos Elite tienen un lead time inferior a una hora. Los equipos de bajo rendimiento tienen lead times de varias semanas o meses.
Un lead time largo no es un problema de velocidad de desarrollo. Es un problema de fricción organizacional: procesos de aprobación demasiado pesados, ramas largas que divergen, suites de pruebas que tardan horas, entornos de staging inestables.
3. Change Failure Rate: ¿qué porcentaje de despliegues causan un incidente?
La tasa de fallos en los cambios mide qué proporción de despliegues en producción requieren una corrección urgente, un rollback, o causan una degradación del servicio.
Los equipos Elite tienen una tasa entre el 0% y el 15%. Los equipos de bajo rendimiento pueden superar el 45%.
Contra la intuición, los equipos que despliegan con más frecuencia generalmente tienen una mejor change failure rate. Los despliegues pequeños y frecuentes son más fáciles de probar, validar y revertir si es necesario. Los grandes despliegues poco frecuentes son más arriesgados, no más seguros.
4. Time to Restore Service: ¿cuánto tiempo para recuperarse de un incidente?
El tiempo de restauración mide cuánto tiempo transcurre entre el inicio de un incidente en producción y su resolución.
Los equipos Elite restauran el servicio en menos de una hora. Los equipos de bajo rendimiento tardan entre una semana y un mes.
Esta métrica refleja la madurez de las prácticas de observabilidad (monitorización, alertas, trazabilidad), la calidad de la documentación de los sistemas y la capacidad del equipo para diagnosticar y corregir problemas rápidamente bajo presión.
¿Por qué estas 4 métricas y no otras?
La correlación con el rendimiento empresarial se estableció estadísticamente a lo largo de varios años de estudios. No es una teoría. Es un resultado empírico.
Los equipos que tienen buen rendimiento en estas 4 métricas tienden a:
- Entregar funcionalidades más rápido
- Tener menos incidentes
- Pagar la deuda técnica más fácilmente
- Tener equipos menos estresados
Otras métricas de uso común - velocidad, story points, número de commits, cobertura de pruebas - no han mostrado una correlación clara con estos resultados. Pueden ser útiles localmente, para diagnosticar un problema específico. No son indicadores de salud organizacional.
El problema de las métricas vanidad
La velocidad es la métrica vanidad por excelencia. Mide cuántos puntos completa un equipo por sprint. El problema: los puntos no están calibrados entre equipos, derivan con el tiempo dentro de un mismo equipo, y recompensan la estimación alta en lugar de la entrega real.
Un equipo puede tener alta velocidad y no entregar nada útil en producción. Un equipo puede tener baja velocidad y entregar valor cada día.
Los story points tienen una utilidad limitada para la planificación interna. Usados como indicadores de rendimiento, crean comportamientos contraproducentes: estimación inflada, división artificial de tickets, optimizar el número en lugar del resultado.
Los tickets cerrados sufren el mismo problema. Cerrar 20 tickets sin valor real de negocio no es rendimiento.
¿Cómo medir las DORA metrics concretamente?
Deployment Frequency: registra cada despliegue en producción con una marca de tiempo. Calcula la frecuencia de los últimos 30 días.
Lead Time for Changes: mide el tiempo entre el primer commit de una rama y el merge a producción. La mayoría de las herramientas CI/CD pueden extraerlo automáticamente.
Change Failure Rate: etiqueta cada incidente en producción con el despliegue que lo causó. Divide por el número total de despliegues.
Time to Restore: registra la hora de inicio y fin de cada incidente. Calcula la media.
Ninguna de estas mediciones requiere una herramienta sofisticada para empezar. Una hoja de cálculo es suficiente para comenzar.
La conexión con la organización del trabajo
Las DORA metrics no mejoran pidiendo al equipo que «lo haga mejor». Mejoran cambiando estructuras y procesos.
Un ciclo de trabajo bien delimitado en Sinra - con issues claras, capabilities definidas y una release objetivo precisa - reduce naturalmente el lead time. Cuando cada issue tiene un alcance claro y una release asociada, el código llega a producción más rápido porque no espera a otras issues para tener sentido.
Las releases bien definidas también permiten medir la change failure rate de forma significativa: cada release es un alcance de cambio documentado, con issues y testings asociados.
La organización del trabajo no está separada del rendimiento técnico. Las DORA metrics lo hacen visible.
¿Por dónde empezar?
Elige una métrica. Solo una. Mídela durante 30 días sin intentar mejorarla. Solo comprende dónde estás.
Luego busca las causas raíz de los malos números. Un lead time largo suele provenir de una revisión de código lenta o de ramas que crecen demasiado. Una change failure rate alta suele provenir de pruebas insuficientes o de un alcance de despliegue demasiado amplio.
Corrige una causa. Mide de nuevo. Itera.
Es más lento que implementar un nuevo marco de rendimiento. Y mucho más efectivo.
¿Listo para Transformar su Gestión de Proyectos?
Aplique estos insights con Sinra, la plataforma unificada para equipos modernos.
Iniciar Prueba Gratuita