LLM, RAG, agents: demystifying the AI concepts invading dev
LLM, RAG, agents, embeddings, MCP - these terms are everywhere in tech discussions. But behind the jargon, what do they actually mean? And more importantly, when should you use them, and when should you be wary?
There is a problem with how the tech world talks about AI right now. Every week brings a new batch of acronyms, every article assumes the reader already knows what it is talking about, and discussions mix concepts that have little to do with each other.
The result: many developers end up using AI tools without really understanding what they do under the hood. That works fine for simple tasks. But it becomes a problem when you need to debug, optimize, or choose the right approach for a project.
Here is a direct explanation of the most frequently recurring concepts, in the order that makes sense to understand them.
LLM: the foundation of everything
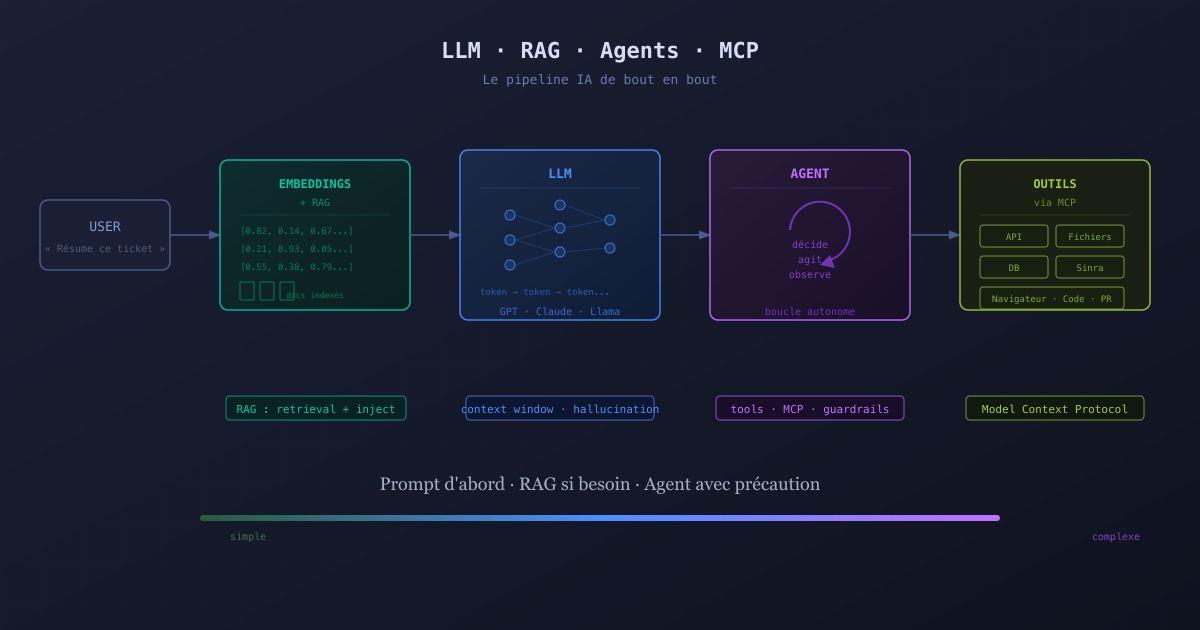
An LLM (Large Language Model) is a statistical model trained on enormous amounts of text. Its fundamental mechanism: predicting the next token (unit of text) from the preceding context. That is all.
From this simple mechanism emerge surprising capabilities: summarization, translation, code generation, reasoning, question answering. GPT-4, Claude, Llama, Mistral - these are all LLMs.
The concrete example: you send “Summarize this text in three points” followed by an article, the LLM produces a summary. It does not “understand” the text in the human sense. It generates a statistically coherent response with what humans would have written in that context.
The limit to know: LLMs hallucinate. They invent facts with the same confidence as they state real ones. Their knowledge is frozen at their training date. And they have no memory between conversations, unless you explicitly provide it.
Prompt engineering: the art of asking well
The prompt is the instruction you send to the LLM. Prompt engineering is the discipline of formulating these instructions in a way that produces reliable, quality results.
A few techniques that make a real difference:
- Few-shot: giving examples in the prompt. “Here are three examples of what I want, now do the same for this case.”
- Chain-of-thought: asking the model to reason step by step before answering. Significantly improves performance on complex tasks.
- System prompt: an upfront context instruction that defines the model’s role and behavior for the entire conversation.
The limit to know: prompt engineering is fragile. A model changes, and your prompts may behave differently. It is hard to test systematically, and small variations in wording can have large effects.
Embeddings: representing meaning as numbers
An embedding is a vector representation of text. Concretely: transforming a sentence into a list of numbers (often several hundred or thousands of dimensions) that captures its semantic meaning.
What makes embeddings useful: two semantically close texts will have close vectors in this mathematical space. “dog” and “canine” will have closer vectors than “dog” and “car”.
The concrete example: you index all your technical documentation as embeddings. When a user asks a question, you calculate the embedding of their question and search for documents whose embeddings are closest. You retrieve the relevant passages, even if the exact phrasing differs.
The limit to know: embeddings measure semantic similarity, not logical relevance. Two sentences can be semantically close while being contradictory. The quality of your embeddings also depends on the model used to generate them.
RAG: giving the LLM memory and fresh data
RAG stands for Retrieval-Augmented Generation. The principle: before calling the LLM, search for relevant documents (via embeddings or traditional search) and inject them into the request context.
This is the answer to the most common problem with LLMs: they do not know what happened after their training date, and they do not know your internal data.
The concrete example: a chatbot that answers questions about your team’s internal documentation. Without RAG, it invents answers. With RAG, you first retrieve relevant doc pages, then ask the LLM to answer using those pages. The result is grounded in real data.
Typical pipeline:
- User asks a question
- Calculate the embedding of the question
- Search for closest documents in the vector database
- Inject those documents into the prompt
- LLM generates a response drawing on those documents
The limit to know: RAG quality is directly tied to retrieval quality. If you retrieve the wrong documents, the LLM will produce a bad answer with a lot of confidence. “Garbage in, garbage out” applies here at full force.
Context window: the LLM’s working memory
The context window is the maximum amount of text an LLM can “see” at once: conversation history, documents injected via RAG, system prompt - all of it together must fit in this window.
It is measured in tokens. Recent models have context windows from 128k to 1 million tokens, corresponding to hundreds of pages of text.
Why it matters: the context window dictates your RAG strategy. If your window is large, you can inject more documents and be less selective. If it is small, you need to be precise about what you retrieve. And every token in the window has a cost - financial and in latency.
Agents: the LLM that acts
An agent is an LLM equipped with tools and capable of making decisions in a loop. Instead of answering a question and stopping there, the agent can call functions, query APIs, read files, and chain multiple actions to accomplish a task.
The concrete example: an agent that receives a Sinra ticket describing a bug. It reads the ticket, searches the relevant code files, identifies the problem, writes a fix, runs the tests, and opens a pull request. All autonomously, deciding at each step what action to take next.
Typical agent loop:
- Read the objective
- Decide which action to take (call a tool, search for info, generate text)
- Execute the action
- Observe the result
- Repeat until the objective is reached (or until failure)
The limit to know: agents are powerful and unreliable on long tasks. They can get stuck in loops, make cascading bad decisions, and errors compound. The longer the task, the higher the risk of going off the rails. Costs can also escalate quickly. Use with clear guardrails.
MCP: the standard for connecting tools to agents
MCP (Model Context Protocol) is an open protocol developed by Anthropic to standardize how LLMs interact with external tools and services.
Without a standard, every integration (LLM + tool) is a custom implementation. MCP defines a common interface: the LLM knows how to request using a tool, the tool knows how to expose its capabilities, and the integration is reusable.
The concrete example: an MCP server exposes Sinra’s capabilities. The agent can then read issues, create cycles, update statuses - without every developer having to write the integration from scratch.
It is the equivalent of a standardized API for the agents world. In 2026, MCP is adopted by the majority of major dev tools.
Fine-tuning: specializing a model
Fine-tuning involves taking an existing LLM and re-training it on your own data to adapt its behavior to your use case. The model learns a response style, a specialty domain, or a particular format.
When it makes sense: when you want to modify tone or style systematically. When performance on a very specific domain is insufficient with prompt engineering alone. When you have thousands of quality examples to train on.
The limit to know: fine-tuning does not serve to “teach facts” to the model. For giving it access to precise and up-to-date information, RAG is almost always the better choice. Fine-tuning is expensive, time-consuming, and gains are often lower than hoped.
Where to start: the escalation rule
When facing a problem to solve with AI, the rule is simple:
First: a good prompt. Often sufficient for 80% of use cases. Simple to iterate, no infrastructure cost.
If data is missing or outdated: add RAG. Index your documentation, your tickets, your knowledge base. The LLM will answer drawing on real facts.
If actions are needed: build an agent. With well-defined tools, clear guardrails, and starting with short, verifiable tasks.
If behavior needs to change deeply: consider fine-tuning. As a last resort, with quality data.
The common trap: jumping straight to agents because it is exciting, without first trying a simple prompt. Complexity has a real cost - in maintenance, debugging, API costs.
What this changes for a product team
For a team using Sinra day-to-day, these tools can have a concrete impact on repetitive tasks: generating a first spec draft from a description, summarizing a cycle’s activity, suggesting labels for a new ticket, identifying similar capabilities that already exist.
The key: stay clear-eyed about what the LLM actually does. It produces probable text. It does not understand your business context. It does not remember the decision made three weeks ago unless you provide it.
Used with this clarity, AI becomes a real accelerator. Used without it, it is a source of undeserved trust in outputs that need to be verified.
Ready to Transform Your Project Management?
Apply these insights with Sinra - the unified platform for modern teams.
Start Free Trial