Trunk-based development vs feature branches: which one to choose?
Long-lived feature branches feel safe. They let you work in isolation, without disturbing anyone. Until merge day, when everything falls apart. Trunk-based development offers a different approach: integrate early, integrate often, and never let code sit idle for too long.
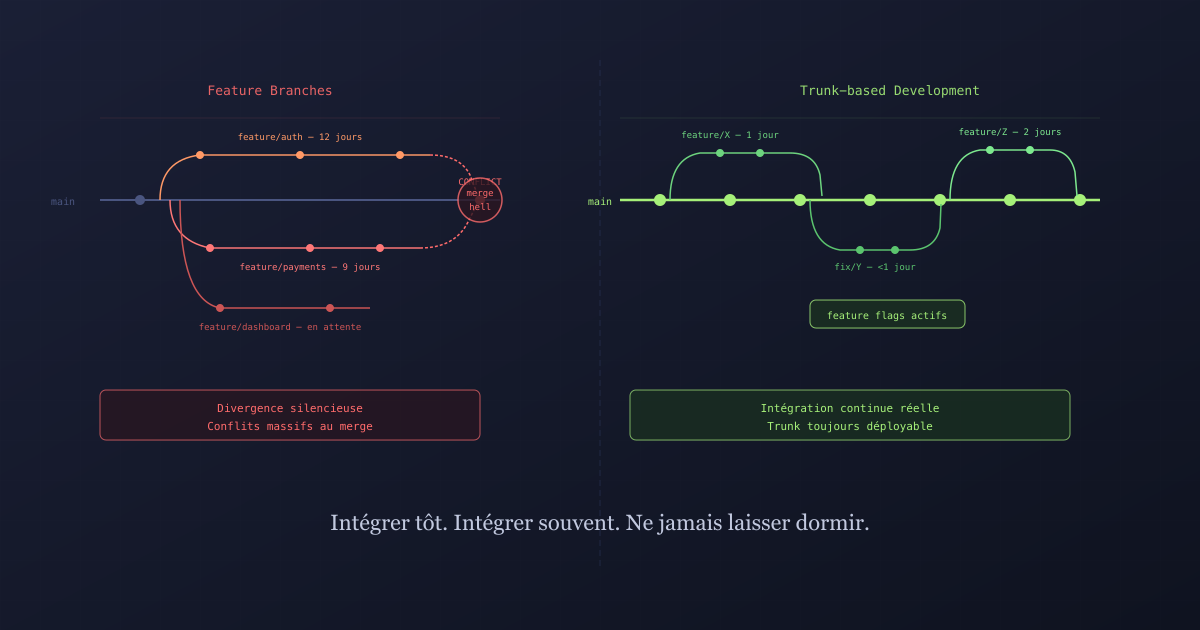
Monday, you create a branch for your new feature. Friday, you try to merge. The conflict is 400 lines long. You spend the afternoon untangling what your colleagues did while you were working in isolation. CI is red. Code review takes two hours because nobody remembers what you explained at the start of the week.
This scenario has a name: merge hell. And it has an identifiable cause: long-lived feature branches.
The problem with long-lived branches
A long-lived feature branch is a branch that lives for several days or weeks in parallel with the rest of the codebase. On paper, the intention is good: isolate work in progress so it doesn’t destabilize the main codebase. In practice, what seems safe creates exactly the problem you were trying to avoid.
While you work on your branch, the rest of the team advances on theirs. The two codebases silently diverge. Nobody sees the accumulating conflicts. When merge time comes, you’re not just integrating your code: you’re integrating several days of simultaneous divergence.
The longer the branch, the more painful the merge. This is an almost mechanical rule.
There’s another less visible effect: code in development on long-lived branches isn’t tested in the real context of the codebase. Integration tests run on snapshots that drift further and further from reality. You discover problems late, when they’re expensive to fix.
What trunk-based development is
Trunk-based development is a practice where all developers integrate their code into the main branch (the “trunk”, often main or master) multiple times per day. Branches exist, but they’re short-lived: a maximum of one or two days.
The core idea: if integration is painful, the solution isn’t to avoid it but to do it more often. The more frequently you integrate, the smaller and simpler the conflicts become.
Concretely, it looks like this:
- You work on a small unit of code (a function, an endpoint, a database migration).
- You create a branch, write the code, open a pull request within the day.
- The review is fast because the diff is small and the context is fresh.
- You merge within the day or the next morning.
- You move to the next unit.
The trunk is always in a deployable state. Continuous integration isn’t a floating concept: it’s a mechanical reality.
The role of feature flags
The main counterargument to trunk-based development: “What if the feature isn’t finished when we merge?”
That’s a real question. The answer is feature flags.
A feature flag is a switch that enables or disables code in production. You can merge incomplete code into the trunk, wrap it in a disabled flag, and expose it progressively when it’s ready. Users see nothing while the flag is off. Your team can test in production on a subset. You can roll back in a second without redeploying.
Feature flags decouple deployment from delivery. Deploying (putting code in prod) becomes distinct from releasing (enabling the feature for users). This distinction profoundly changes risk management.
Concrete advantages of trunk-based development
Conflicts are small. When you integrate multiple times per day, each integration touches little code. Conflicts, when they occur, resolve in minutes.
Code reviews are useful. A 30-line diff on a branch opened yesterday is reviewable. An 800-line diff on a branch opened two weeks ago is a formality everyone wants to get rid of.
Continuous integration is real. CI doesn’t validate isolated code: it validates the current state of the entire system. Regressions appear immediately, not on Friday evening before a release.
There’s less work in progress. WIP decreases. The team works on things that are actually moving forward rather than on branches waiting to merge.
The codebase is always deployable. You can deploy at any time. No need to plan a “merge window” or freeze development before a release.
When long-lived feature branches make sense
Trunk-based development isn’t universal. There are contexts where long-lived branches are justified, even necessary.
Open source projects. When external contributors submit code, you can’t ask them to integrate directly on the trunk. Long pull requests exist to allow review of contributions whose cadence you don’t control.
Teams with a slow review process. If code review systematically takes several days because reviewers are overwhelmed, keeping branches short is difficult. But in this case, the problem to solve isn’t branching: it’s review capacity.
Major structural changes. An architecture migration, replacing a foundational library: these efforts sometimes require a dedicated branch. But even there, techniques like “branch by abstraction” allow progressive integration into the trunk without long-lived branches.
The usual resistance
“We can’t do trunk-based, we have too many features in parallel.”
It’s often the opposite: features in parallel on long-lived branches create exactly the complexity that makes everything difficult. Less simultaneous work in progress, with shorter cycles, mechanically simplifies integration.
“Developers aren’t comfortable with that.”
It’s a matter of habit. Most developers who have worked trunk-based don’t want to go back to long-lived branches. The friction of change is real, but it’s temporary.
“We need branches for code review.”
Code review doesn’t require long-lived branches. It requires pull requests - which can be opened and merged within the day.
The connection with short cycles
Trunk-based development works naturally with short delivery cycles. When your team works with well-defined cycles, with clear objectives for each iteration, breaking work into small integratable units becomes the natural way to work.
In Sinra, cycles allow you to precisely define what’s in progress at any given moment. Issues are the units of work. Capabilities group the features to be delivered in a release. This structure naturally favors short branches: each issue corresponds to a unit of work that can be integrated quickly, without waiting for weeks of development to accumulate.
Releases are thus composed of code that has already been integrated and validated, not branches fighting to be right at the last moment.
In practice: how to start
If your team currently works with long-lived branches, the transition to trunk-based development happens progressively.
Start by reducing the maximum lifetime of branches. Set a rule: no branch can live more than two days without being merged or broken into smaller pieces. This forces a different approach to breaking down work.
Next, install a feature flag system if you don’t have one. This is the safety net that lets you integrate incomplete code without risk to users.
Improve review speed. If PRs wait two days before being reviewed because reviewers are overloaded, trunk-based development won’t work. Review must be a priority, not an interruption.
Finally, measure. Lead time for changes (time between the first commit and deployment to prod) is a direct measure of the efficiency of your integration process. If this time decreases, you’re moving in the right direction.
Trunk-based development isn’t an absolute rule. It’s a direction: integrate more often, keep branches short, never let code sit idle. Merge pain isn’t inevitable. It’s the symptom of too-infrequent integration.
Ready to Transform Your Project Management?
Apply these insights with Sinra - the unified platform for modern teams.
Start Free Trial